Welcome to Henry's blog! A work in progress
Optimizers
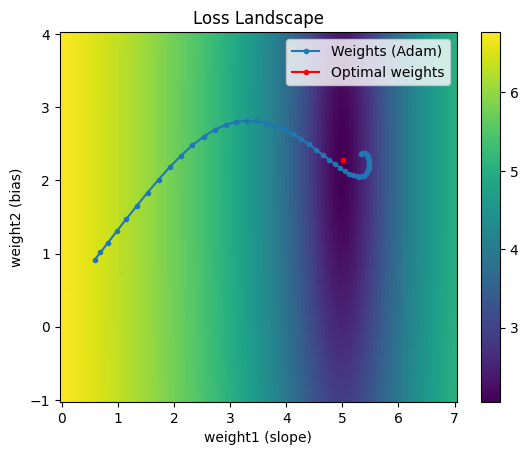
In a previous post we explored using vanilla gradient descent for linear regression in the process of motivating activation functions for nonlinear function approximation. We saw that while we were able to estimate reasonable parameters, it took a while for the loss to converge due to the problem of pathological curvature. In this post we solve... Read more 29 Jul 2024 - 10 minute read
Building a Transformer From Scratch
One of the cornerstones of the seemingly weekly advancements in AI research and applications is the transformer architecture, introduced in Attention Is All You Need by Vaswani, et al in 2017. I felt the magic for myself last year when I tried out Andrej Karpathy’s nanoGPT project and was able to train a character-level language model on my Mac ... Read more 24 Mar 2024 - 15 minute read
Building a Mini Neural Network Library: Backpropagation and Autograd
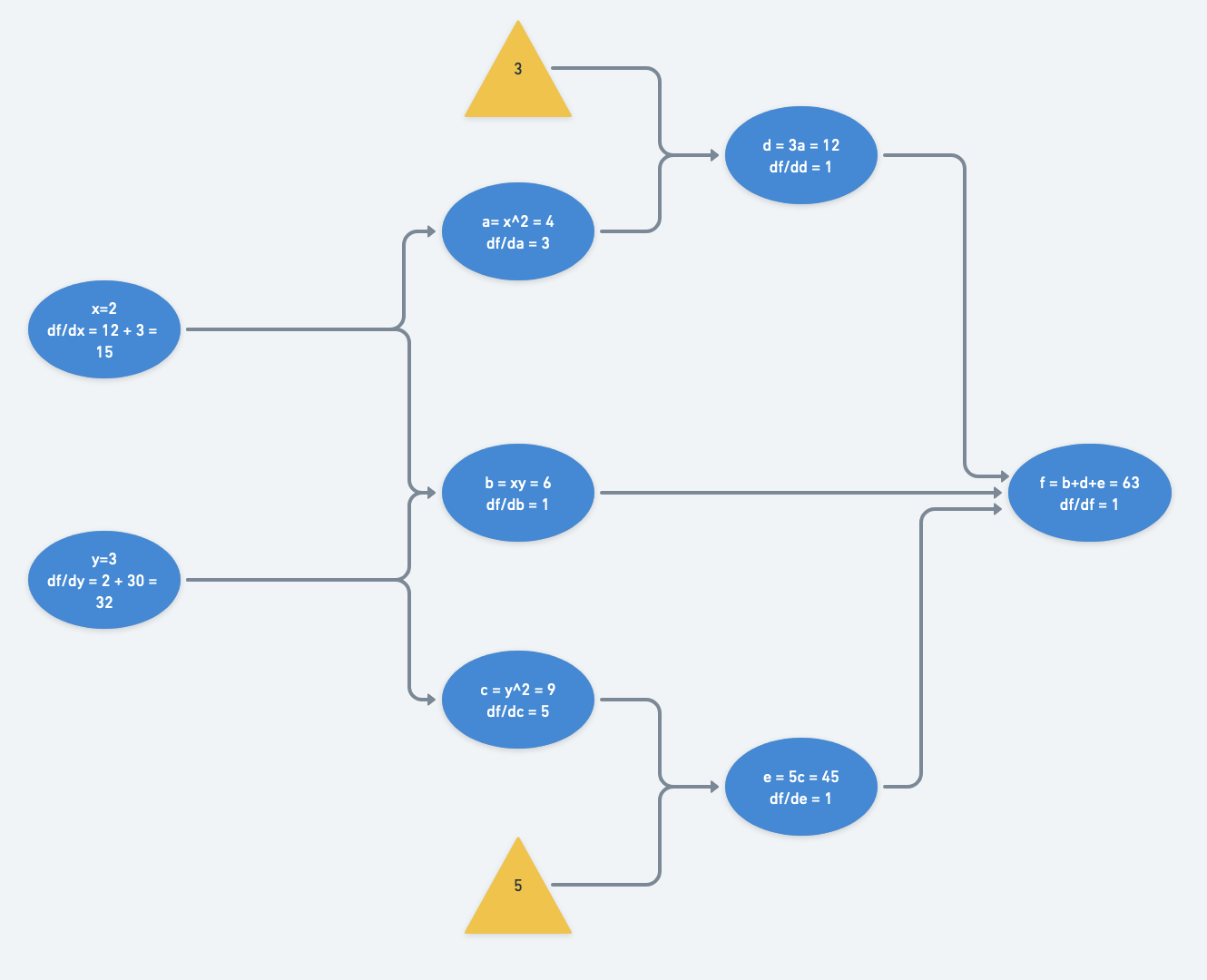
This blog post accompanies minigrad, a mini autograd engine for tensor operations and a small neural network library on top of it. Going through a typical training loop, we would see the following steps: Run input data through the model to generate logits. Calculate the loss by comparing the logits with the labels via a loss function. Ba... Read more 17 Feb 2024 - 11 minute read
ResNet From Scratch
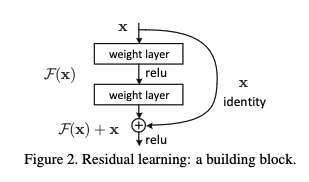
ResNets were considered state-of-the-art CNNs for many tasks in computer vision until the last couple years. In this post, we’ll first walk through the paper that introduced the idea of residual networks, then dive deep into implementing our own ResNets from scratch. We’ll implement our own torch.nn.Modules for each layer and look deep under the... Read more 04 Feb 2024 - 26 minute read
Function Approximation with Deep Learning
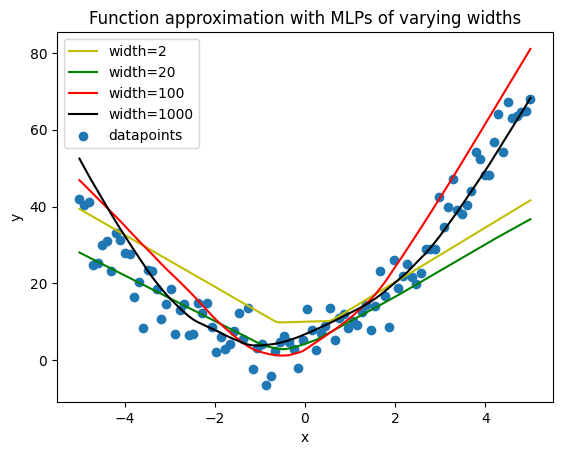
From linear regression to non-parametric nonlinear regression In this post, we build up some intuition around how deep learning can be used for approximating any function. We start off with recalling how linear regression is performed and then motivate and demonstrate how a neural network can be used for non-parametric nonlinear regression. Yo... Read more 29 Jan 2024 - 9 minute read