
One of the most commonly used datasets in ML research has been the MNIST dataset. It’s a small dataset containing 60,000 28x28 greyscale images of handwritten digits and their labels, with 10 distinct classes for the digits from 0-9. It’s often used as a “Hello World” example for machine learning.
In this post, we go from doing some exploratory data analysis, through fully-connected models, up to training our first CNN model and achieving >99% classification accuracy on the dataset. Along the way, we write our own Learner class from scratch and use it to group together model, loss, optimizer, training and validation datasets.
This work was inspired by this notebook from the Fast.ai course, Practical Deep Learning for Coders.
You can choose to follow along directly in Colab, or read the summary below.
![]()
Import torchvision MNIST
We download the MNIST dataset from torchvision. As part of the download, we can specify any transformations to make to the data inputs or to the data labels. Here, we only transform the data inputs. To be able to properly do machine learning with images, we need to turn them from PIL images to PyTorch Tensors.
import torchvision.transforms as T
from torchvision.datasets import MNIST
from torch.utils.data import Subset, DataLoader
import torch
train_dataset = MNIST(root='mnist', train=True, download=True, transform=T.ToTensor())
test_dataset = MNIST(root='mnist', train=False, download=True, transform=T.ToTensor())
A first look at the data
Each image is a 3D tensor with a single channel (first dimension) and height and width of 28. We can get the image and label of the ith sample of the dataset like so:
int i = 0
image = train_dataset[i][0]
label = train_dataset[i][1]
It’s good practice to normalize input data to make the optimization landscape smoother so that it takes fewer iterations to converge to a good minimum. With pandas DataFrames, we can easily notice all the values have already been normalized to be between 0 and 1, with 1 corresponding with “black” and 0 with “white.”
import pandas as pd
df = pd.DataFrame(torch.squeeze(train_dataset[0][0]))
df.style.set_properties(**{'font-size':'5pt'}) \
.background_gradient('Greys').format(precision=2)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 3 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 4 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.07 | 0.07 | 0.07 | 0.49 | 0.53 | 0.69 | 0.10 | 0.65 | 1.00 | 0.97 | 0.50 | 0.00 | 0.00 | 0.00 | 0.00 |
| 6 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.12 | 0.14 | 0.37 | 0.60 | 0.67 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.88 | 0.67 | 0.99 | 0.95 | 0.76 | 0.25 | 0.00 | 0.00 | 0.00 | 0.00 |
| 7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.19 | 0.93 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | 0.36 | 0.32 | 0.32 | 0.22 | 0.15 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 8 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.86 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.78 | 0.71 | 0.97 | 0.95 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.31 | 0.61 | 0.42 | 0.99 | 0.99 | 0.80 | 0.04 | 0.00 | 0.17 | 0.60 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | 0.60 | 0.99 | 0.35 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.55 | 0.99 | 0.75 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.75 | 0.99 | 0.27 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.14 | 0.95 | 0.88 | 0.63 | 0.42 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.32 | 0.94 | 0.99 | 0.99 | 0.47 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 15 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.18 | 0.73 | 0.99 | 0.99 | 0.59 | 0.11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.06 | 0.36 | 0.99 | 0.99 | 0.73 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.98 | 0.99 | 0.98 | 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.18 | 0.51 | 0.72 | 0.99 | 0.99 | 0.81 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 19 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.15 | 0.58 | 0.90 | 0.99 | 0.99 | 0.99 | 0.98 | 0.71 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.09 | 0.45 | 0.87 | 0.99 | 0.99 | 0.99 | 0.99 | 0.79 | 0.31 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 21 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.09 | 0.26 | 0.84 | 0.99 | 0.99 | 0.99 | 0.99 | 0.78 | 0.32 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 22 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.67 | 0.86 | 0.99 | 0.99 | 0.99 | 0.99 | 0.76 | 0.31 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.22 | 0.67 | 0.89 | 0.99 | 0.99 | 0.99 | 0.99 | 0.96 | 0.52 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.53 | 0.99 | 0.99 | 0.99 | 0.83 | 0.53 | 0.52 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 26 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 27 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
We can also check the distribution of the dataset, and see that it’s approximately uniform across number of samples of each digit.
Create a validation dataset
It’s important to carefully split out a validation set from the training set to use to see how well the model generalizes to unseen data during training.
import numpy as np
validation_frac = 0.2
num_samples = len(train_dataset)
split_idx = int(np.floor((1 - validation_frac) * num_samples))
train_idx = np.arange(split_idx)
valid_idx = np.arange(split_idx, num_samples)
train_data = Subset(train_dataset, train_idx)
valid_data = Subset(train_dataset, valid_idx)
Load Datasets into DataLoaders
torch.utils.data.Dataset and torch.util.data.DataLoader are the two primitives used in PyTorch to decouple pre-loaded data and data for model training.
Datasets, as we saw above, store inputs and their labels, and its elements can be accessed like with a Python dictionary.
DataLoaders, on the other hand, are more useful when training a model.
“We typically want to pass samples in “minibatches”, reshuffle the data at every epoch to reduce model overfitting, and use Python’s multiprocessing to speed up data retrieval.
DataLoader is an iterable that abstracts this complexity for us in an easy API.”
Source: PyTorch data tutorial
One aspect of DataLoaders to keep in mind is the batch size parameter. Batch size can be dependent on dataset and architecture, both in terms of training stability and in terms of memory capacity. A larger batch size results in more stable training since the variance in gradient estimation per batch is reduced. However a larger batch size can cause the GPU to run out of memory.
We start experimenting with a batch size that is the length of the entire dataset and update it below for different approaches as needed. Note for our first baseline that no gradients are computed so batch size has no influence on “convergence speed.”
train_dataloader = DataLoader(train_data, batch_size=len(train_data), shuffle=True)
valid_dataloader = DataLoader(valid_data, batch_size=len(valid_data), shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=len(test_dataset), shuffle=True)
Pixel Similarity baseline model
Now we can start trying to create a model to classify the images as digits. Our first model takes a non-ML approach in favor of a straightforward elementwise pixel to pixel comparison per image. We compare a sample image to a mean image for each digit. The mean image is computed by averaging over the training examples per digit.
First we calculate the mean image per digit.
train_data_by_digit = {}
valid_data_by_digit = {}
for i in range(10):
train_data_by_digit[i] = \
torch.stack([sample[0] for sample in Subset(train_dataset, list(filter(lambda x: x < split_idx, digit_indices[i])))])
valid_data_by_digit[i] = \
torch.stack([sample[0] for sample in Subset(train_dataset, list(filter(lambda x: x >= split_idx, digit_indices[i])))])
digit_means = {y: torch.Tensor() for y in range(10)}
for i in range(10):
digit_means[i] = train_data_by_digit[i].mean(axis=0)
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(torch.squeeze(digit_means[i]), cmap=plt.get_cmap('gray'))
plt.show()

Next, we can make predictions based on pixel-wise comparisons.
import torch.nn.functional as F
def predict(sample):
# choose the digit whose mean image is closest to the sample
return torch.argmin(torch.tensor([F.l1_loss(sample, torch.squeeze(digit_means[i])) for i in range(10)]))
def predict_batch(samples):
return torch.tensor([predict(torch.squeeze(sample)) for sample in samples])
preds = torch.empty(0)
labels = torch.empty(0)
for batch in test_dataloader:
images, ls = batch
preds = torch.cat((preds, predict_batch(images)), dim = 0)
labels = torch.cat((labels, ls), dim = 0)
Lets see our prediction accuracy for this baseline:
accuracy = torch.sum(torch.eq(labels, preds)) / len(labels)
print(accuracy)
tensor(0.6673)
Lets also see the confusion matrix. It’s interesting that if guessing incorrectly, it’s likely to be guessing the digit 1, which makes some sense!
from sklearn.metrics import confusion_matrix
import seaborn as sn
cf_matrix = confusion_matrix(labels, preds)
df_cm = pd.DataFrame(cf_matrix / np.sum(cf_matrix, axis=1)[:, None], index = [i for i in range(10)],
columns = [i for i in range(10)])
plt.figure(figsize = (10,10))
sn.heatmap(df_cm, annot=True)
plt.show()
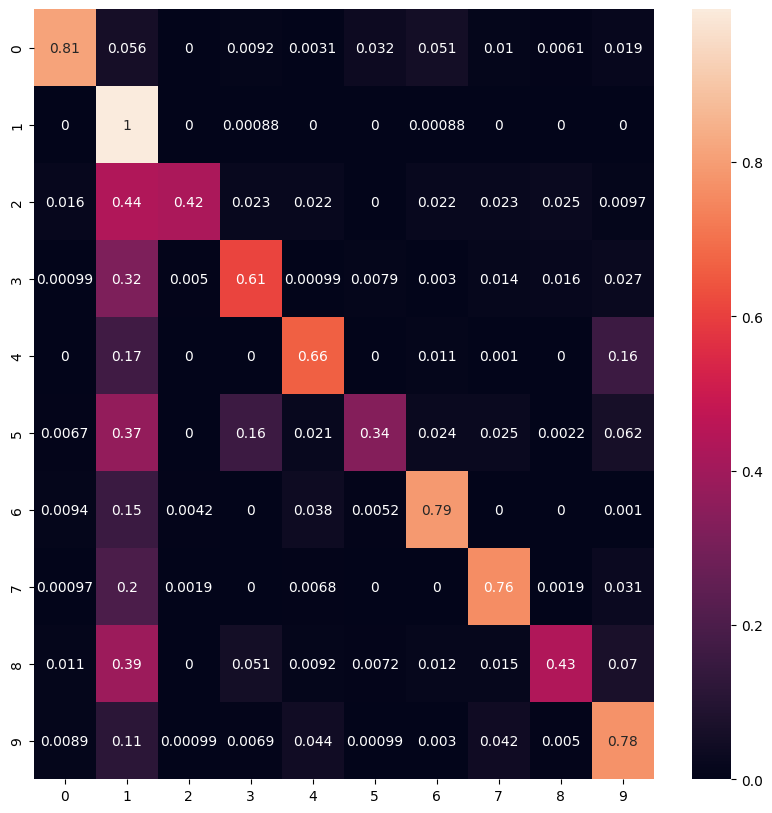
I’m surprised by how good this baseline already is, without any ML (>60% classification accuracy), but we can definitely do better.
Learner class from scratch
There is a 7 step process for iterating on model weights:
- Initialize params
- Calculate predictions
- Calculate the loss
- Calculate the gradients
- Step the parameters
- Repeat the process
- Stop
Lets implement a class that does this.
class Learner:
def __init__(self, dataloaders, model, optimizer, loss_func, metric, scheduler=None):
self.dataloaders = dataloaders
self.model = model
self.optimizer = optimizer
self.loss_func = loss_func
self.metric = metric
self.scheduler = scheduler
self.val_losses = []
def fit(self, epochs):
for epoch in range(epochs):
print("---- epoch: ", epoch, "/", epochs - 1, " ----")
self.model.train()
train_loss = 0.
for (train_features, train_labels) in self.dataloaders.train_dl():
preds = self.model(train_features)
loss = self.loss_func(preds, train_labels)
train_loss += loss
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
if self.scheduler:
self.scheduler.step()
print("avg training loss: ", train_loss / len(self.dataloaders.train_dl()))
self.model.eval()
with torch.no_grad():
# We evaluate on the entire validation dataset
val_preds = []
val_labels = []
for (val_features, val_ls) in self.dataloaders.valid_dl():
val_preds.append(self.model(val_features))
val_labels.append(val_ls)
val_preds = torch.squeeze(torch.stack(val_preds, dim=0))
val_labels = torch.squeeze(torch.stack(val_labels, dim=0))
val_loss = self.loss_func(val_preds, val_labels)
print("validation loss: ", val_loss)
print("metric: ", self.metric(val_preds, val_labels))
# Early stopping
self.val_losses.append(val_loss)
if len(self.val_losses) > 2 and self.val_losses[-1] > self.val_losses[-2] and self.val_losses[-2] > self.val_losses[-3]:
print("stopping condition met")
break
We also create a class to group together training and validation datasets that our Learner needs.
class DataLoaders:
def __init__(self, train_dataloader, valid_dataloader):
self.train_dataloader = train_dataloader
self.valid_dataloader = valid_dataloader
def train_dl(self):
return self.train_dataloader
def valid_dl(self):
return self.valid_dataloader
Train a linear model
Now that we have a Learner class, we can train a linear model for sanity checking and to get another baseline. We still need a few concrete components in order to train: an architecture, an optimizer, and a loss function. Additionally, with a Linear model, we need to work with flattened data. We use the flattened dataset that was prepared in the colab notebook, but not shown here.
bs = 64
lr = 1e-1
train_dataloader = DataLoader(train_data_flat, batch_size=bs, shuffle=True, drop_last=True)
valid_dataloader = DataLoader(valid_data_flat, batch_size=len(valid_data), shuffle=True)
test_dataloader = DataLoader(test_dataset_flattened, batch_size=len(test_dataset_flattened), shuffle=True)
dls = DataLoaders(train_dataloader, valid_dataloader)
This is the metric we’ll use to see how well each model is able to classify digits.
def digit_accuracy(preds, labels):
return (torch.argmax(preds, axis=1) == labels).float().mean()
We’ll use this same loss function for all our models.
loss_func = torch.nn.CrossEntropyLoss()
Now let’s construct our model and optimizer, then feed all of them to a Learner.
model = torch.nn.Linear(28*28,10)
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
learner = Learner(dls, model, optimizer, loss_func, digit_accuracy)
learner.fit(1)
---- epoch: 0 / 0 ----
avg training loss: tensor(0.5105, grad_fn=<DivBackward0>)
validation loss: tensor(0.3485)
metric: tensor(0.9063)
Let’s see the test accuracy.
test_feats, test_labels = next(iter(test_dataloader))
preds = model(test_feats)
print("test accuracy: ", digit_accuracy(preds, test_labels))
test accuracy: tensor(0.9065)
Cool, looks like our linear model has learned something about handwritten digits and has a big improvement over the pixel-wise comparison baseline. But a linear model can only learn so much; a nonlinear model has more wiggle room (pun-intended) to fit the data.
Train a feed-forward network model
ffn_model = torch.nn.Sequential(torch.nn.Linear(28*28, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 10)
)
lr = 1e-1
ffn_optimizer = torch.optim.SGD(ffn_model.parameters(), lr=lr)
learner = Learner(dls, ffn_model, ffn_optimizer, loss_func, digit_accuracy)
learner.fit(10)
---- epoch: 0 / 9 ----
avg training loss: tensor(0.4878, grad_fn=<DivBackward0>)
validation loss: tensor(0.2750)
metric: tensor(0.9197)
---- epoch: 1 / 9 ----
avg training loss: tensor(0.2544, grad_fn=<DivBackward0>)
validation loss: tensor(0.2246)
metric: tensor(0.9354)
---- epoch: 2 / 9 ----
avg training loss: tensor(0.2006, grad_fn=<DivBackward0>)
validation loss: tensor(0.1842)
metric: tensor(0.9498)
---- epoch: 3 / 9 ----
avg training loss: tensor(0.1664, grad_fn=<DivBackward0>)
validation loss: tensor(0.1586)
metric: tensor(0.9557)
---- epoch: 4 / 9 ----
avg training loss: tensor(0.1429, grad_fn=<DivBackward0>)
validation loss: tensor(0.1455)
metric: tensor(0.9603)
---- epoch: 5 / 9 ----
avg training loss: tensor(0.1257, grad_fn=<DivBackward0>)
validation loss: tensor(0.1348)
metric: tensor(0.9604)
---- epoch: 6 / 9 ----
avg training loss: tensor(0.1118, grad_fn=<DivBackward0>)
validation loss: tensor(0.1280)
metric: tensor(0.9630)
---- epoch: 7 / 9 ----
avg training loss: tensor(0.1015, grad_fn=<DivBackward0>)
validation loss: tensor(0.1214)
metric: tensor(0.9647)
---- epoch: 8 / 9 ----
avg training loss: tensor(0.0919, grad_fn=<DivBackward0>)
validation loss: tensor(0.1220)
metric: tensor(0.9635)
---- epoch: 9 / 9 ----
avg training loss: tensor(0.0843, grad_fn=<DivBackward0>)
validation loss: tensor(0.1135)
metric: tensor(0.9672)
test_feats, test_labels = next(iter(test_dataloader))
preds = ffn_model(test_feats)
print("test accuracy: ", digit_accuracy(preds, test_labels))
test accuracy: tensor(0.9701)
That’s decent accuracy, but we can do better and use fewer parameters by taking advantage of the spatial structure of an image!
Train a CNN
from torch import nn
def conv(ni, nf, stride=2, ks=3):
return nn.Conv2d(ni, nf, kernel_size=ks, stride=stride, padding=ks // 2)
simple_cnn_model = nn.Sequential(
conv(1,8, ks=5), #14x14
nn.ReLU(),
conv(8,16), #7x7
nn.ReLU(),
conv(16,32), #4x4
nn.ReLU(),
conv(32,64), #2x2
nn.ReLU(),
conv(64,10), #1x1
nn.Flatten()
)
simple_cnn_optimizer = torch.optim.SGD(simple_cnn_model.parameters(), lr=1e-2)
bs = 128 # larger batch size means more stable training, but fewer opportunities to update parameters
# Use the unflattened data
train_dataloader = DataLoader(train_data, batch_size=bs, shuffle=True)
valid_dataloader = DataLoader(valid_data, batch_size=len(valid_data), shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=len(test_dataset), shuffle=True)
dls = DataLoaders(train_dataloader, valid_dataloader)
learner = Learner(dls, simple_cnn_model, simple_cnn_optimizer, loss_func, digit_accuracy)
learner.fit(3)
---- epoch: 0 / 2 ----
avg training loss: tensor(2.3014, grad_fn=<DivBackward0>)
validation loss: tensor(2.3006)
metric: tensor(0.1060)
---- epoch: 1 / 2 ----
avg training loss: tensor(2.2990, grad_fn=<DivBackward0>)
validation loss: tensor(2.2983)
metric: tensor(0.1060)
---- epoch: 2 / 2 ----
avg training loss: tensor(2.2957, grad_fn=<DivBackward0>)
validation loss: tensor(2.2936)
metric: tensor(0.1060)
Uh oh…the model doesn’t train very well…we’re going to need a few tricks.
Train a performant CNN to achieve high accuracy on MNIST
Learning rate scheduling: 1cycle training
1cycle LR training allows us to stably use a much higher learning rate than if we had kept a static learning rate through the entire training process. It updates the learning rate after every batch, annealing from some low learning rate up to a maximum learning rate, then back down to a rate much lower than the initial rate.
scheduler = torch.optim.lr_scheduler.OneCycleLR(simple_cnn_optimizer, max_lr=0.06, steps_per_epoch=len(train_dataloader), epochs=10)
learner = Learner(dls, simple_cnn_model, simple_cnn_optimizer, loss_func, digit_accuracy, scheduler)
learner.fit(10)
---- epoch: 0 / 9 ----
avg training loss: tensor(1.3388, grad_fn=<DivBackward0>)
validation loss: tensor(0.2145)
metric: tensor(0.9356)
---- epoch: 1 / 9 ----
avg training loss: tensor(0.1783, grad_fn=<DivBackward0>)
validation loss: tensor(0.1195)
metric: tensor(0.9630)
---- epoch: 2 / 9 ----
avg training loss: tensor(0.1070, grad_fn=<DivBackward0>)
validation loss: tensor(0.1086)
metric: tensor(0.9668)
---- epoch: 3 / 9 ----
avg training loss: tensor(0.0745, grad_fn=<DivBackward0>)
validation loss: tensor(0.0813)
metric: tensor(0.9746)
---- epoch: 4 / 9 ----
avg training loss: tensor(0.0585, grad_fn=<DivBackward0>)
validation loss: tensor(0.0750)
metric: tensor(0.9786)
---- epoch: 5 / 9 ----
avg training loss: tensor(0.0452, grad_fn=<DivBackward0>)
validation loss: tensor(0.0807)
metric: tensor(0.9772)
---- epoch: 6 / 9 ----
avg training loss: tensor(0.0346, grad_fn=<DivBackward0>)
validation loss: tensor(0.0608)
metric: tensor(0.9822)
---- epoch: 7 / 9 ----
avg training loss: tensor(0.0232, grad_fn=<DivBackward0>)
validation loss: tensor(0.0598)
metric: tensor(0.9825)
---- epoch: 8 / 9 ----
avg training loss: tensor(0.0142, grad_fn=<DivBackward0>)
validation loss: tensor(0.0584)
metric: tensor(0.9847)
---- epoch: 9 / 9 ----
avg training loss: tensor(0.0093, grad_fn=<DivBackward0>)
validation loss: tensor(0.0596)
metric: tensor(0.9846)
And evaluating on the test set:
test_feats, test_labels = next(iter(test_dataloader))
preds = simple_cnn_model(test_feats)
print("test accuracy: ", digit_accuracy(preds, test_labels))
test accuracy: tensor(0.9862)
We’re close to our goal of >99% accuracy, but our metrics show we’re plateauing. Let’s add another technique in the mix to try to make better use of our neural capacity.
Batch Normalization
Batch normalization was invented to address “internal covariate shift,” and although the issue being solved is debatable, there’s no doubt that batch normalization makes training a CNN much easier. This normalization technique finds a mean and variance for activations in a minibatch, reducing the number of activations that are too large or too small (the exploding/vanishing gradient problem).
Whereas a learning rate scheduler warms up to a higher learning rate, with batch norm we can just start off with a high learning rate. We can also acheive even higher accuracy in fewer iterations.
cnn_model_with_norm = nn.Sequential(
conv(1 ,8, ks=5), #14x14
nn.BatchNorm2d(8),
nn.ReLU(),
conv(8 ,16), #7x7
nn.BatchNorm2d(16),
nn.ReLU(),
conv(16,32), #4x4
nn.BatchNorm2d(32),
nn.ReLU(),
conv(32,64), #2x2
nn.BatchNorm2d(64),
nn.ReLU(),
conv(64,10), #1x1
nn.BatchNorm2d(10),
nn.Flatten()
)
optimizer = torch.optim.SGD(cnn_model_with_norm.parameters(), lr=1e-2)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, steps_per_epoch=len(train_dataloader), epochs=10)
learner = Learner(dls, cnn_model_with_norm, optimizer, loss_func, digit_accuracy, scheduler)
learner.fit(10)
---- epoch: 0 / 9 ----
avg training loss: tensor(0.3510, grad_fn=<DivBackward0>)
validation loss: tensor(0.1048)
metric: tensor(0.9712)
---- epoch: 1 / 9 ----
avg training loss: tensor(0.0883, grad_fn=<DivBackward0>)
validation loss: tensor(0.0819)
metric: tensor(0.9755)
---- epoch: 2 / 9 ----
avg training loss: tensor(0.0605, grad_fn=<DivBackward0>)
validation loss: tensor(0.0589)
metric: tensor(0.9831)
---- epoch: 3 / 9 ----
avg training loss: tensor(0.0439, grad_fn=<DivBackward0>)
validation loss: tensor(0.0440)
metric: tensor(0.9859)
---- epoch: 4 / 9 ----
avg training loss: tensor(0.0331, grad_fn=<DivBackward0>)
validation loss: tensor(0.0475)
metric: tensor(0.9865)
---- epoch: 5 / 9 ----
avg training loss: tensor(0.0259, grad_fn=<DivBackward0>)
validation loss: tensor(0.0409)
metric: tensor(0.9877)
---- epoch: 6 / 9 ----
avg training loss: tensor(0.0189, grad_fn=<DivBackward0>)
validation loss: tensor(0.0351)
metric: tensor(0.9893)
---- epoch: 7 / 9 ----
avg training loss: tensor(0.0136, grad_fn=<DivBackward0>)
validation loss: tensor(0.0321)
metric: tensor(0.9902)
---- epoch: 8 / 9 ----
avg training loss: tensor(0.0090, grad_fn=<DivBackward0>)
validation loss: tensor(0.0320)
metric: tensor(0.9903)
---- epoch: 9 / 9 ----
avg training loss: tensor(0.0061, grad_fn=<DivBackward0>)
validation loss: tensor(0.0317)
metric: tensor(0.9905)
test_feats, test_labels = next(iter(test_dataloader))
preds = cnn_model_with_norm(test_feats)
print("test accuracy: ", digit_accuracy(preds, test_labels))
test accuracy: tensor(0.9924)
That’s pretty good classification accuracy! Lets look at a few examples for ourselves and see our classification accuracy with our own eyes.
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.title(torch.argmax(preds[i]))
plt.imshow(torch.squeeze(test_feats[i]), cmap=plt.get_cmap('gray'))
plt.show()

Awesome! Looks like we’re able to recognize handwritten digits pretty well. On to something more challenging…